【文系向け】大規模言語モデル(LLM)って一体なんだ?生成AIと何が違うの?

最終更新日:2024/11/05 公開日:2024/01/27
ChatGPTに代表される生成AIの説明に当たって、必ず「大規模言語モデル」(LLM= large language model)というものが出てきます。この大規模言語モデルって一体なんでしょう?生成AIを理解する上でとても大事なキーワードなので、文系・非技術者の方でも3分でわかるようにざっくりご説明します。詳細を知りたい方は他の会社さんのサイトをご覧頂くとして、ここでは分かりやすさに全振りして解説します。
そもそも言語モデルって何だろう?
言語モデルとは、コンピュータが人間の言葉を理解し、出力するために単語の次に来る単語の、出現確率を使ってパターン化したものです。
例えば
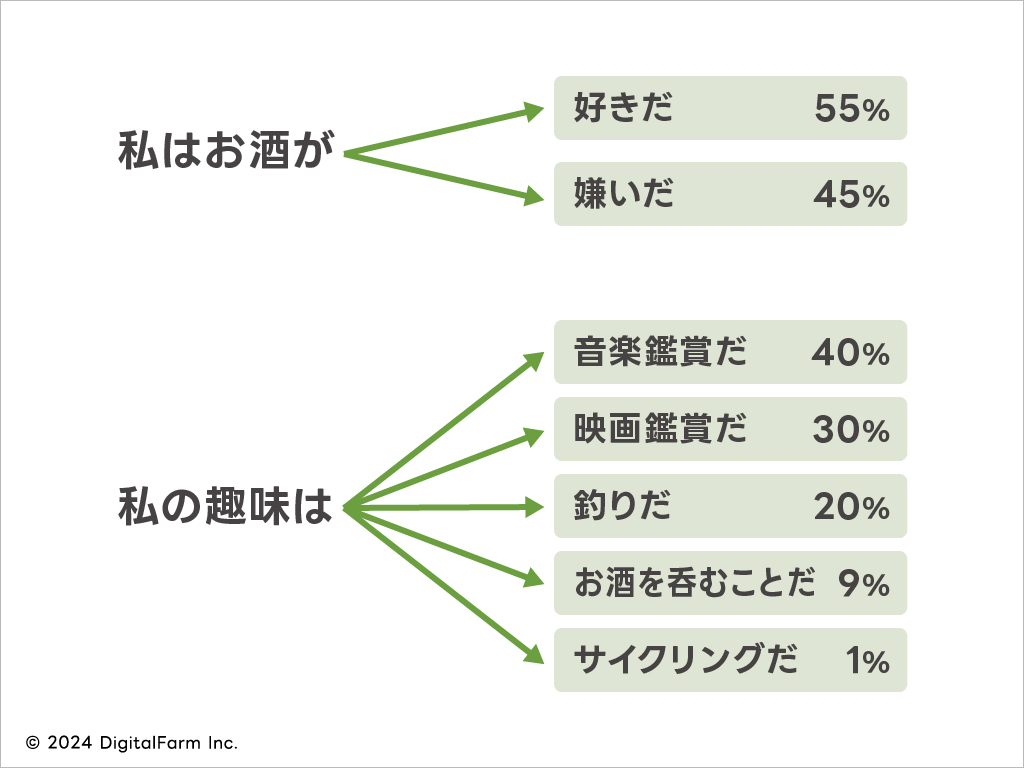
というような並んだ単語に対して、次に来る確率分布です。
この確率分布の精度をあげるために、インターネットをなどを活用し、大規模なデータを学習させた言語モデルが大規模言語モデルです。
大規模言語モデル(LLM)の定義。
様々なサイトで大規模言語モデル(LLM)が定義されていますが、一番引用数が多いと(勝手に)思われるNVIDIAのサイトを見てみましょう。
- 大規模言語モデル (LLM) は、膨大なデータセットから得た知識に基づいて、テキストやその他のコンテンツを認識、要約、翻訳、予測、生成できるディープラーニング アルゴリズムです。
大規模言語モデルの用途とは? | NVIDIA
膨大なデータセットというのはどういう意味かというと、狭い意味では1+1は2です、というような質問と答えのセットのことを言います。しかし、LLMではそもそもこのような質問と答えがセットになってないデータを学習させることも良くあります。
大規模言語モデル(LLM)と生成AIとの違い
簡単に言うと「大規模言語モデル(LLM)」はテキストデータしか扱えません。テキストの意味を理解、咀嚼し、生成することに特化しています。音声や動画は扱えません。何しろ名前が言語モデルですから、そりゃそうですね。他方「生成AI」は画像や音声、動画までを幅広く扱う事が出来ます。扱う事が出来る対象がテキストか、それ以外もか、という違いです。言うなれば焼き肉屋さんが焼き肉だけ食べられるのか、お寿司も食べられるのかの違いです。
ChatGPTはLLMなの?それとも生成AI?
ChatGPTは「今は」生成AIですが、以前は大規模言語モデル(LLM)でした。どういう事かというと、そもそもChatGPTはサービス名であり、開発しているのはOpenAIという会社です。この会社は当初ディープラーニングの学習手法を使った大規模言語モデル、GPT-3.5(Generative Pre-trained Transformer 3.5)を提供しいました。このGPT-3.5は2020年7月にリリースされましたが、ここまではテキストしか扱う事が出来なかったのです。その次のバージョンGPT-4になってから画像も取り扱うことが出来る用になりました。
つまり、GPT-3.5までは大規模言語モデル(LLM)で、以降は生成AI、という事になります。
ちなみに本記事のサムネ映像はChatGPT-4oに「LLMのイメージを書いて」と御願いして描いて貰いました。お、おう。。。
\Webサイトに生成AIによる検索システムを組みこみたい/
お気軽にお問い合わせください。進化が早い分野なので低コストでサクッと開発出来るのが何よりも大事な分野です。
ご相談・お問い合わせする